Para sites pequenos, o Googlebot entra, lê tudo e vai embora. Para sites grandes (mais de 10.000 páginas únicas com atualizações frequentes, ou sites com mais de 1 milhão de páginas), o Google possui recursos limitados.
Ele não vai rastrear todas as suas páginas se você não souber direcioná-lo. É aqui que entra a gestão do Crawl Budget (Orçamento de Rastreamento).
1. A Matemática do Crawl Budget
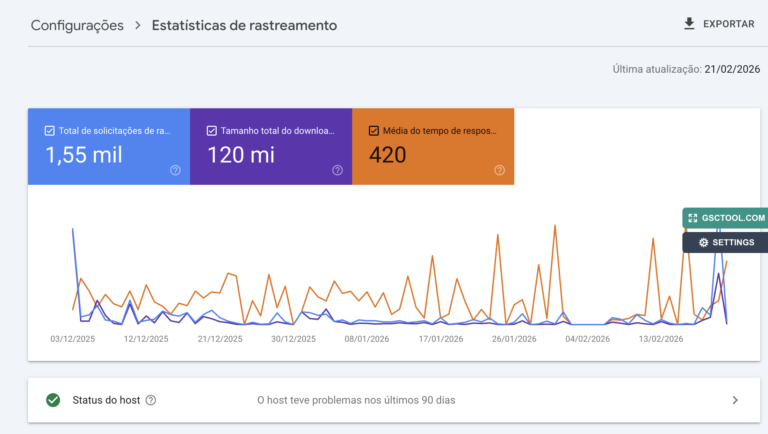
O Crawl Budget é a quantidade de tempo e recursos que o Googlebot está disposto a gastar rastreando o seu site. Ele é determinado por dois fatores principais:
- Limite de Capacidade de Rastreamento (Host Load): O quanto o seu servidor aguenta sem cair. Se o seu tempo de resposta do servidor (TTFB) for alto, o Googlebot reduz a taxa de rastreio para não derrubar o seu site.
- Demanda de Rastreamento (Crawl Demand): O quão popular e atualizado é o seu site. URLs com alta autoridade (PageRank) e atualizações frequentes são rastreadas com mais frequência.
Se o Googlebot perde tempo rastreando milhares de páginas inúteis, ele pode não rastrear seus novos produtos, artigos ou atualizações críticas.
2. O Novo Cenário de Rastreamento: O Limite Estrito de 2MB
Uma das mudanças técnicas mais drásticas e urgentes no SEO moderno é a severa redução no limite de rastreamento. O Google reduziu o limite de leitura de 15MB para apenas 2MB por página.
O que isso significa tecnicamente? Se o peso da sua página (somando HTML, scripts bloqueantes, CSS inline e mídia não otimizada no carregamento inicial) exceder 2MB, o Googlebot simplesmente interrompe o download no meio do caminho. O resultado é a Indexação Parcial.
- Seus links internos no rodapé não serão vistos.
- A relevância semântica cai por falta de leitura completa do conteúdo.
- Consequentemente, você sofre com perda de rankings e queda drástica de tráfego orgânico.
Para um site grande, manter o código extremamente limpo, usar lazy loading agressivo para imagens fora da tela inicial e adiar (defer) scripts não essenciais é agora uma questão de sobrevivência técnica no rastreamento.
3. O Inimigo Nº 1 dos Grandes Sites: Navegação Facetada e “Crawler Traps”
Em grandes e-commerces, a navegação facetada (filtros de categoria) é o maior ralo de Crawl Budget existente.
Imagine uma categoria de sapatos. Você tem filtros de Tamanho, Cor, Marca e Preço. O sistema começa a gerar URLs combinadas dinamicamente:
- /sapatos?type=running
- /sapatos?type=running&brand=adidas
- /sapatos?type=running&brand=adidas&size=10
Para o Googlebot, cada combinação dessas é tratada como uma página separada. Isso gera uma quantidade quase infinita de URLs (“Index Bloat” e “Crawl Bloat”), criando armadilhas de rastreamento (Crawler Traps) onde o bot fica preso lendo páginas quase idênticas.
A Solução Técnica para Navegação Facetada:
- A Ilusão da Canonical Tag: Muitos acham que usar a tag rel=”canonical” resolve o problema. É um erro. A canonical tag ajuda a evitar conteúdo duplicado e consolida sinais de ranking, mas não economiza Crawl Budget. O Googlebot ainda precisa rastrear a página para ler a tag.
- O Bloqueio via Robots.txt: A forma mais direta de salvar o orçamento de rastreamento é usar o robots.txt (Ex: Disallow: /*?color=*). Isso impede o Googlebot de perder tempo nessas páginas.
- A Arquitetura Ideal (AJAX/Fetch API): A melhor prática técnica em 2025 é construir a navegação facetada usando JavaScript (Fetch API/AJAX). Em vez de usar links tradicionais com a tag HTML <a> nos filtros, use <button> ou <span> acionando eventos JS, modificando a URL via History API. Como o Googlebot não segue links que não sejam <a href=”…”>, ele não descobrirá as infinitas combinações, erradicando o problema pela raiz.
4. Análise de Log do Servidor (Log File Analysis): A Verdade Absoluta
Ferramentas como o Google Search Console mostram uma visão limitada. Se você quer saber exatamente como o Google rastreia seu site de grande porte, você precisa analisar os Logs de Acesso do Servidor (usando ferramentas como Screaming Frog Log File Analyser ou Oncrawl).
Os logs revelam os “hits” exatos do User-Agent do Googlebot. Ao analisá-los, um SEO Técnico descobre:
- Orphan Pages (Páginas Órfãs): Páginas que estão no sitemap ou recebendo tráfego, mas não possuem links internos apontando para elas.
- Desperdício de Crawl: Você pode ver, por exemplo, que o Googlebot gastou 60% do seu Crawl Budget diário batendo em URLs de paginação antiga ou arquivos de parâmetros de pesquisa inativos.
- Frequência de Rastreio: Com que rapidez o bot descobre e rastreia novas publicações.
5. Escoamento de PageRank e Arquitetura de Links Internos (Siloing)
O Google rastreia seguindo links. A forma como você estrutura suas ligações internas determina como o “Link Juice” (ou PageRank) flui e quão rápido as páginas são rastreadas.
- Profundidade de Clique (Click Depth): Nenhuma página importante em um site de 1 milhão de URLs deve estar a mais de 3 ou 4 cliques de distância da página inicial (Homepage).
- Breadcrumbs (Trilhas de Navegação): Essenciais para grandes sites. Eles fornecem links internos escaláveis e perfeitamente estruturados em silos, permitindo que o Google entenda a hierarquia exata (Ex: Home > Eletrônicos > Smartphones > Samsung).
- Paginação Otimizada: Para grandes categorias, garanta que a paginação utilize as tags corretas e que seja rastreável, ou que haja páginas de “Ver Todos” bem otimizadas, para que os produtos nas páginas finais não fiquem órfãos.
Conclusão
Rastrear um site gigante não é sobre o algoritmo “gostar” do seu conteúdo; é sobre eficiência computacional.
O Googlebot é um software com orçamento limitado. Como SEO Técnico, seu trabalho é atuar como um engenheiro de tráfego: fechar estradas inúteis (bloqueios no robots.txt e JavaScript em facetas), limpar obstáculos da via (manter o peso do HTML rigorosamente abaixo de 2MB para evitar indexação parcial) e construir rodovias expressas (arquitetura rasa e links internos lógicos) direto para o seu conteúdo mais lucrativo.